728x90
1. INDEX ?
- 지정한 컬럼들을 기준으로 메모리 영역에 일종의
목차를 생성하는 것이다. INSER, UPDATE, DELETE(Command)의 성능을 희생하고SELECT(Query)의 성능을 향상시킨다.- 즉, “내가 원하는 부분을 쉽고 빠르게 찾아서 전달해주는 역할”을 한다.
- “정보 검색”에 있어 성능을 최적화시켜줄 수 있는 유용한 도구
2. INDEX의 동작
- 동작순서
- DMBS는 INDEX를 다향한 알고리즘으로 관리를 하고 있다.
- 일반적으로 사용되는 자료구조는
B+Tree이다.
a. `Index Table`에서 `WHERE`에 포함된 값을 찾는다. b. 해당 값의 `table_id [PK]`을 가져온다. c. 가져온 `table_id [PK]`값 으로 원본 테이블에서 값을 조회한다.
B+Tree이다.
3. B+Tree
- MySQL에서 사용하는 하므로, 다른 Database의 경우 index의 동작원리가 상이할 수도 있다.
이진트리→B-Tree→B+Tree순으로 확장되었다.
1 ) Clustered Index 와 Non Clustered Index
Clustered Index: 개발자가 설정하는 Index가 아닌 MySQL이 자동으로 설정하는 Index- Auto Increments 값으로 PK가 있다면 해당 컬럼이
Clustered Index가 된다. - PK가 없다면 Unique 컬럼으로 선정한다.
- Unique 컬럼도 없다면 MySQL에서 내부적으로
Hidden Clustered Index Key (row ID)를 만들어 사용한다.
- Auto Increments 값으로 PK가 있다면 해당 컬럼이
Non Clustered Index: 개발자 또는 DBA등이 설정하는 모든 Index.- 멀티 컬럼 Index의 경우 최대 16개의 컬럼을 사용할 수 있다.
- 테이블 당 인덱스의 개수는 최대 64개까지 지정이 가능하다.
2 ) B+Tree 의 구조
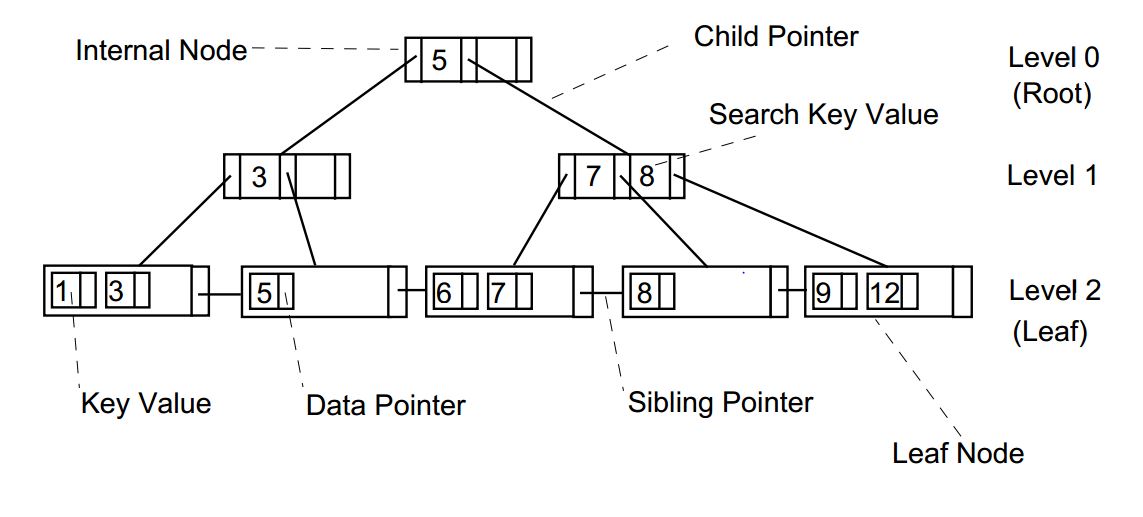
각각의 사각형 하나를 Node 혹은 Page라고 부르며, MySQL에서는 가장 큰 효율이 나는 사이즈인 16KB로 설정되어있다.
- 구성
- 리프 노드 : 실제 데이터가 저장되는 노드
- 논리 노드 : 리프 노드까지의 경로 역학을 하는 노드
- 루트 노드 : 경로의 출발점 노드
- 이점
- 리프 노드에 이르기까지 자식 노드에 대한 포인터가 저장되어 있다.
- 즉, 루트 노드에서 어떤 리프 노드에 리는 한 개의 경로만 검색하면 된다.
4. INDEX의 설정
- 데이터양이 많을 때
- 표와 같이 데이터양에 비례해서
Index Scan의 효율을 증가한다.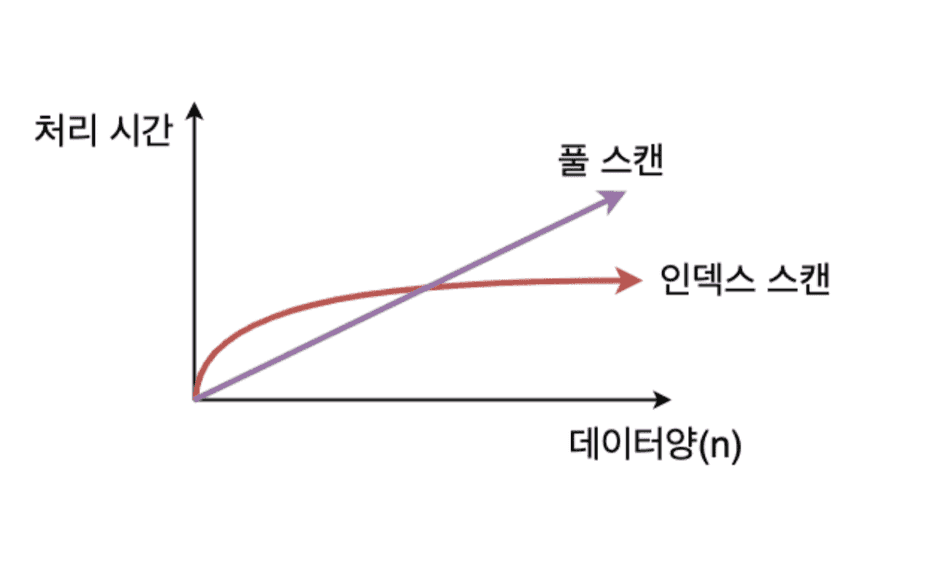
- 표와 같이 데이터양에 비례해서
- 카디널리티 (Cardinality)
- 카디널리티가 높을 수록 인덱스 설정에 좋은 컬럼이다.
- 카디널리티가 높다 = 한 컬럼이 갖고 있는 중복도가 낮다.
- 카디널리티가 낮다 = 한 컬럼이 갖고 있는 중복도가 높다.
- 선택도 (Selectivity)
- 선택도가 낮으면 인덱스 설정에 좋은 컬럼이다. (일반적으로 5~10%)
- 선택도가 높다 = 한 컬럼이 갖고 있는 값 하나로 여러 row가 찾아진다.
- 선택도가 낮다 = 한 컬럼이 갖고 있는 값 하나로 적은 row가 찾아진다.
- 활용도
- 활용도가 높을 수록 인덱스 설정에 좋은 컬럼이다.
- 해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값.
- 중복도
- 중복도가 없을 수록 인덱스 설정에 좋은 컬럼이다.
- 수정 빈도
- 수정 빈도가 낮으면 인덱스 설정에 좋은 컬럼이다.
5. INDEX의 재정렬
[DB Index 동작원리를 알아보자
B+Tree를 통해 알아보는 Index 동작 원리
kyungyeon.dev](https://kyungyeon.dev/posts/66)
본 블로그에서 INSERT와 DELETE 의 예제를 통해 더 자세한 과정을 알아볼 수 있다
'SQL' 카테고리의 다른 글
| MySQL Select 조회 성능을 위한 Index 적용기 (0) | 2022.08.04 |
|---|---|
| 스프링 테스트에서의 @Transactional (0) | 2022.04.20 |
| 트랜잭션 (Transaction) (0) | 2022.04.20 |